Validating backups
Sunday, September 04, 2022
My backup strategy
We all know (I hope!) the importance of keeping backups of data. My data backup strategy has been two-fold: using a pair of hard drives locally and a NAS with RAID-11.
The weakest link in this backup strategy is the local hard drives. Currently, I use a pair of 8 TB Western Digital Blue drives, which have been put in service in August. These are installed as a pair to provide redundancy to the backups and to afford some resilience against drive failures2. I’ve been using this pair-of-hard-drives arrangement for a while, and the latest pair is the 4th generation.
The first generation of the backup was a pair of 3 TB drives (Seagate?), followed by a pair of 6 TB (WD), then a pair of hot 8 TB Toshiba drives. The 7200 RPM Toshiba drives were put into service last year, but the high operational temperatures (above 50 ℃) made me very uncomfortable. When the CMR3 8 TB WD drives came on the market, I took the opportunity to swap out the hot 8 TB drives4.
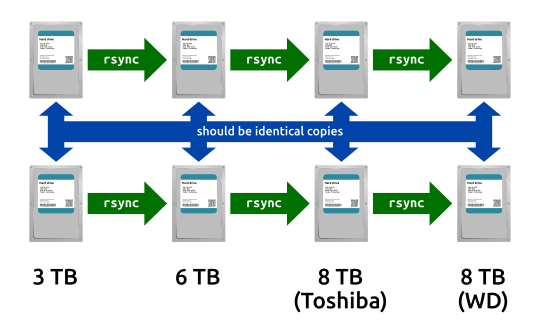
To the main topic, when switching to a new generation of drives, I use rsync to copy data from the old drive to the new drive.
Furthermore, I run the copy from old drive to the new drive independently for each of the pair of drives.
The reasoning behind making copies independently is to reduce the chances of replicating data that underwent bit rot.
Having two independently cloned copies of data would improve the chances to detect the broken data and replace it with a good one.
The find-issues-in-my-backups tool
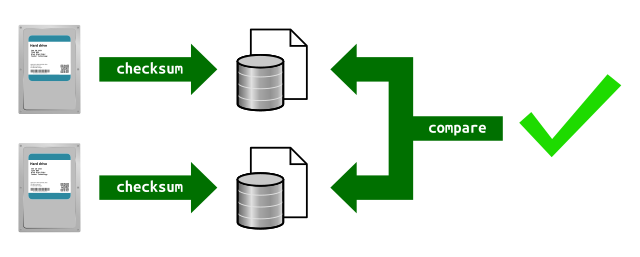
So, how can I find potentially broken data? The only way to check is to check the contents of each file in a disk and compare it with the corresponding file in the other disk.5 A common way to accomplish this is by calculating checksums of data and comparing them.
To calculate the checksums of my backup files, I wrote an application in Rust to accomplish this. The application calculates the checksum (SHA-256 hashes) and stores them in a SQLite database. To compare the two backups, I run the application once on each copy. Once the checksum database of the two backups are created, the application can compare the checksums and report them. (While at it, it gives any differences in files in the directory tree since that’s a trivial endeavor.)
Step 1: Making the checksums
As mentioned above, the first step is to scan through all the files to calculate checksums of the files.
To quickly calculate checksums, an important criteria was the hashing speed.
Fortunately, Rust creates very fast binaries and many libraries in Rust is optimized for performance.
The sha2 library was used, as it’s a widely-used library and could manage to hash data at over 400 MB/s.
Another technical decision made for this step was to forego multithreaded processing. As the backups are on conventional hard drives, one cannot expect much speed up by introducing multithreading. In fact, it’s likely to lead to slower performance, as it could introduce random reads which are much slower on hard drives.
Therefore, this step runs at around 100-200 MB/s where the hard disk’s I/O becomes the bottleneck.
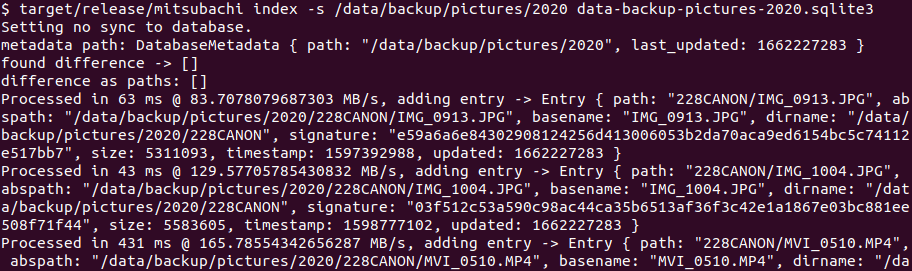
Each file that’s processed is written as a record in a SQLite database with the checksum and other metadata like last modified times. The metadata is used to allow incremental checksum calculations – allowing to break the checksum processing at any time. Allowing incremental processing was important as running the process continuously will get the hard drives to run hot. Furthermore, I can continue to use the same SQLite database later without having to scan the entire disk again.
Finally, I disabled syncing by SQLite using PRAGMA synchronous = OFF.
The reason for this isn’t for performance but for the longevity of the SSD.
With synchronous on higher settings, I noticed that SQLite would be constantly writing a write-ahead log and deleting it.
Deletes are especially hard on SSD longevity, as they occur at block levels, like 512 KB per operation.
Once setting the above PRAGMA, the amount of writes to the SSD dropped significantly.
While it may be vulnerable to database corruption if the OS crashes before the data is persisted to disk, but that’s not very likely to happen.
(Worst case, I can run the process again, although it will take about a day.)
Step 2: Comparison
The comparison step simply opens a couple of SQLite databases and runs a SQL statement to compare the checksum between the files.
It’s literally a single JOIN statement between tables in the two databases:
SELECT
main.entries.path,
main.entries.abspath,
main.entries.signature,
main.entries.timestamp,
second.entries.abspath,
second.entries.signature,
second.entries.timestamp
FROM
main.entries
LEFT JOIN
second.entries ON main.entries.path = second.entries.path
WHERE
second.entries.path IS NOT NULL
AND main.entries.signature != second.entries.signature
The process for the two backup copies takes only about half a second.
The tool in action
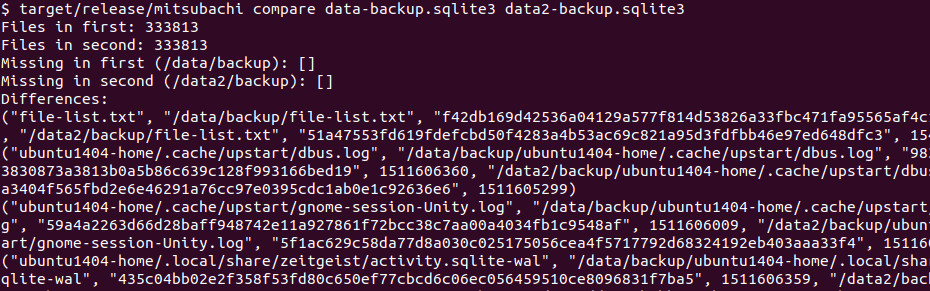
It’s minimalist as it’s a tool for myself to use. That said, it has enough information to tell that the backup copies have the same set of files and that some files are different. In this example, there’s 333,813 files in each set of backups, which some files have differences which are expected.6
Now that I know that my backups appear not to have any bit-rot. Next step is to use transition to a redundant solution that doesn’t involve manually making backup copies. 😉
-
Unfortunately, no offsite backup strategy yet. ↩
-
I’ve been bitten by the IBM “Deathstars” back in the early 2000s and other hard drive failures in later years. ↩
-
Little bit jarring everytime I realize “conventional magnetic recording” is just perpendicular magnetic recording (PMR) which was a new thing in the mid 2000s. Thanks world for making me feel old. 😛 ↩
-
Yes, the WD CMR drives are lower RPM than the Toshiba, but it still can reach up to 200 MB/s, which is good enough. ↩
-
Sidenote: Many RAID and some filesystems (e.g. ZFS) have scubbing that checks data integrity by checking file/block contents between drives in a volume. ↩
-
As the backups were made at slightly different moments, differences were detected in log files and zeitgeist index files, which should come as no surprise. ↩